Raw Music From Free Movements
Abstract
Raw Music from Free Movements is a deep learning architecture that translates pose sequences into audio waveforms. The architecture combines a sequence-to-sequence model generating audio encodings and an adversarial autoencoder that generates raw audio from audio encodings. Experiments have been conducted with two datasets: a dancer improvising freely to a given music, and music created through simple movement sonification. The paper presents preliminary results. These will hopefully lead closer towards a model which can learn from the creative decisions a dancer makes when translating music into movement and then follow these decisions reversely for the purpose of generating music from movement.
Implementation

Examples
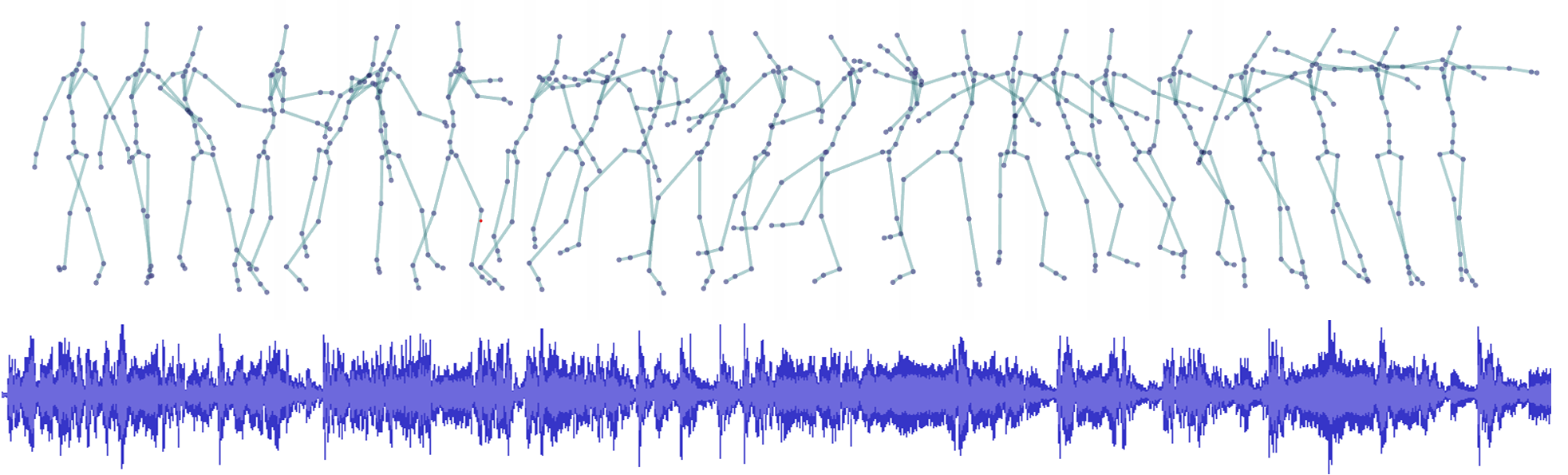
Two different datasets were employed for training, named improvisation dataset and sonification dataset. The improvisation dataset consists of pose sequences and audio that have been recorded while a dancer was freely improvising to a given music. The dancer is an expert with a specialisation in contemporary dance and improvisation. The music consists of short excerpts of royalty free music including experimental electronic music, free jazz, and contemporary classic. The pose sequences have been acquired using the markerless motion capture system (The Captury ) in the iLab at MotionBank, University for Applied Research, Mainz. The recording is 10 minutes in length which corresponds to a sequence of 30000 poses. Each pose consists of 29 joints whose relative orientations are represented by quaternions.
The sonification dataset contains the same pose sequences as the improvisation dataset. The audio of this dataset was created afterwards, through sonification, employing a very simple sound synthesis consisting of two sine oscillators controlled by the dancer’s hands. The frequency and amplitude of each oscillator are proportional to the height and velocity of the corresponding hand, respectively. The authors created this dataset to verify the performance of RAMFEM.
Resources
Code: Bitbucket
Paper: AIMC 2021
Supplementary Materials (Datasets + Code in Paper + Examples): Zenodo
The authors’ thanks go to the dancers who have contributed countless hours o their spare time to the motion capture recordings. Further thanks go to MotionBank for providing their infrastructure and assisting in the recordings. This research is conducted in the context of a Marie Curie Fellowship and is funded byPaper: AIMC 2021
Supplementary Materials (Datasets + Code in Paper + Examples): Zenodo
Acknowledgements
the European Union. The collaboration of the second author has been supported by the Canada Council for the Arts.

